
Tutorial Blog to upload large file to Amazon S3 Glacier using AWS CloudShell.
- Vaibhav Deshpande
- Feb 15, 2024
- 5 min read
This blog is created by Rucha Kulkarni.
Learning Objectives:
• Learn to create an Amazon S3 Glacier vault.
• Learn to upload large file (archives) to Amazon S3 Glacier using AWS CloudShell.
Step 1: Create a vault in Amazon S3 Glacier.
In AWS console, in search bar, type S3 Glacier and go to AWS S3 Glacier.

In S3 Glacier, click on Create vault.

In Create vault, under Vault name, enter the name of the vault and keep the rest as default.

Keep the event notifications as default and click on create vault.

As you can see, the vault is created successfully.

Now, go to CloudShell, which is at the bottom left corner of your console (or to the right of your search bar as well).

Once you click on the CloudShell icon, a terminal interface will appear as below.
In the terminal session of AWS CloudShell, run the yum update command to ensure the latest security updates and bug fixes are installed.
For Amazon Linux:
sudo yum -y update

Step 1 (Alternate):
To create a vault in Amazon S3 Glacier, use the create-vault command to create a vault named awsvault.
Replace the hyphen character by the account-id of your aws account.
aws glacier create-vault --account-id - --vault-name awsvault

Note: You can either create the vault from the S3 Glacier console (step 1) or from the CloudShell terminal (step 1-alternate) by running the create-vault command.
Step 2:
Generate a file to upload.
The command below, will create a file named as newfile.
It contains 3MB of random data.
dd if=/dev/urandom of=newfile bs=3145728 count=1

Note:
‘dd’: Copies data from an input file to an output file.
‘if=/dev/urandom ‘: Source of random data.
‘of=newfile ‘: Specify the output file as newfile.
‘bs ‘: Sets the block size to 3145728 bytes (3MB). Specifies the amount of data that ‘dd’ reads and writes.
‘count=1’: Only one block should be copied.
Note: ‘bs’ and ‘count’ parameters can be adjusted according to the size of file we need to create.
Now, split the file in to 3 chunks of 1MB (1,048,576 byte) using the command:
split -b 1048576 --verbose newfile chunk

Step 3:
Now initiate a multipart upload.
In the below command, replace your account id in place of hyphen & then run the command.
aws glacier initiate-multipart-upload --account-id - --archive-description "multipart upload test" --part-size 1048576 --vault-name awsvault

Before moving to the next step, ensure to save this uploadId for future use.
Copy the uploadId from your console and save it in the variable UPLOADID, so that you do not need to enter your uploadId separately for every command.
UPLOADID="TlNxyc1qeDgZrMY7OfllM5TMqkJP0iLuM9mOXxzxP4I8exp2QU5a1CUVtdL2lGJuxB2R4rnzIYMZCcMVuNAQXDDDVJee "
Note: Make sure that you replace the accountId in place of ‘–‘, and no need to replace the uploadId since we stored it above in a different variable.
Step 4:
Now let us, upload the files in 3 chunks which we had split earlier
aws glacier upload-multipart-part --upload-id $UPLOADID --body chunkaa --range 'bytes 0-1048575/*' --account-id - --vault-name awsvault
Note: For chunkaa – 0MB TO 1MB (1048575 bytes) file size upload

Note: For chunkaa – 1MB TO 2MB (2097151 bytes) file size upload
aws glacier upload-multipart-part --upload-id $UPLOADID --body chunkab --range 'bytes 1048576-2097151/*' --account-id - --vault-name awsvault

Note: For chunkaa – 2MB TO 3MB (3145727 bytes) file size upload
aws glacier upload-multipart-part --upload-id $UPLOADID --body chunkac --range 'bytes 2097152-3145727/*' --account-id - --vault-name awsvault
Step 5:
Now, complete the upload.
Since, we have divided the file into separate chunk of data tree hash checks the data integrity ensuring that data is not lost during upload. Also, it helps in error detection in case the tree hash does not match the expected value.
To calculate a tree hash
1. Split the original file into 1 MB parts. This we have already done in step 3 above.
2. Calculate and store the binary SHA-256 hash of each chunk.
openssl dgst -sha256 -binary chunkaa > hash1
openssl dgst -sha256 -binary chunkab > hash2
openssl dgst -sha256 -binary chunkac > hash3

Combine the first two hashes and take the binary hash of the result
cat hash1 hash2 > hash12
openssl dgst -sha256 -binary hash12 > hash12hash
Combine the parent hash of chunks aa and ab with the hash of chunk ac and hash the result, this time outputting hexadecimal. Store the result in a shell variable.
cat hash12hash hash3 > hash123
openssl dgst -sha256 hash123

Note: Copy this above result(SHA256) from your console and store it in variable $TREEHASH
TREEHASH=”97a16640619816e6355ca79abc416dc06bfb5d8dc1c44b58408ecc99aebef4bc”
Run the ‘ls’ (means list) command to ensure that the hash files and chunks are created.

Step 6:
Now, complete the upload with complete-multipart-upload command.
Replace the hyphen character by your own accountId.
aws glacier complete-multipart-upload --checksum $TREEHASH --archive-size 3145728 --upload-id $UPLOADID --account-id - --vault-name myvault

Note: Save this archiveId for future use.
When you check the status of the vault using the describe-vault command, it will show the no. of archives and size as ‘0’ even though the archives are uploaded.
Replace the hyphen character with your own account id.
aws glacier describe-vault --account-id - --vault-name awsvault
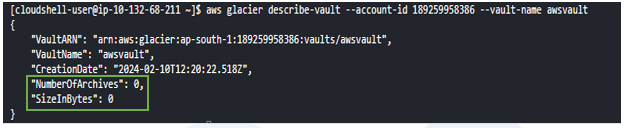
However, after 10-12 hours, again run the describe-vault command and the no. of archives (‘1’) and file size of 3 MB can be seen.

Note: You can also see the status of your vault in Amazon S3 Glacier console, by clicking on the vault name awsvault.

Here also you can see the no. of archives (1) and file size (3 MB) similar to the cloud shell.

Step 7: Remove the archive.
Now, after some time, we can safely remove the chunk and hash files from the created ‘awsvault’. For this use the remove command,
rm chunk* hash*

As the ls command is executed, it is seen that the chunks and hash files are removed.
Now, to empty the vault and delete the archive, run the following command.
aws glacier delete-archive --vault-name awsvault --account-id - --archive-id="*** archiveid ***"
Note: Replace ***archiveid*** with your own archiveId which we saved earlier
Note: After you run the delete-archive command, it will take 1 day to update your vault. After that you can delete vault directly from AWS S3 Glacier console.
As you can see, no. of archives and size are ‘0’ (after 10-12 hours) which means that the archive is deleted and the vault is now empty.

Step 8:
Since the vault is now empty, to delete the vault run the delete-vault command.
aws glacier delete-vault –-vault-name awsvault –account-id –
After running this command, you will not see any outcome for 10-12 hours, then it will automatically delete the vault.
Or you can delete it directly from your S3 Glacier console (after 10-12 hours).

Note: please do not forget to delete the vault to avoid any AWS charges.
Was this document helpful? How can we make this document better. Please provide your insights. You can download PDF version for reference.
For your aws certification needs or for aws learning contact us.
very useful sir
Helpful blog sir
Easy to follow
very useful sir
well defined